
타이타닉 데이터 분석 프로젝트 후기❓
타이타닉 데이터분석 프로젝트를 진행하면서 느꼈던 궁금증 해결하기!!!
1. NULL Data 채우는 다양한 방식
데이터 분석 초기 과정에서 가장 중요한 일 중 하나가 바로 결측치/결측값 처리이다.
여기에 따라 모델 생성과 결과 도출에 이르기까지 큰 영향을 끼치기 때문이다.
-
첫번째 방법, 제거하기
-
목록삭제(Listwise)
결측치가 존재하는 전체 행을 삭제
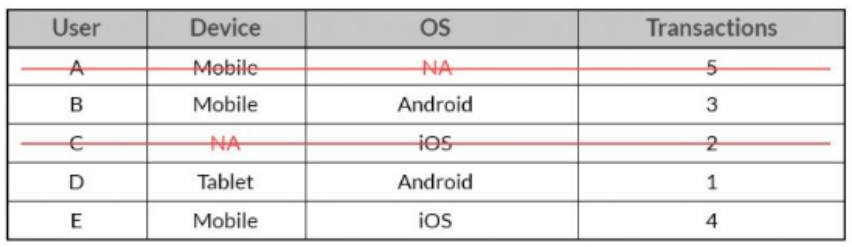
-
단일값 삭제(Pairwise)
손실된 관측치 자체만 삭제
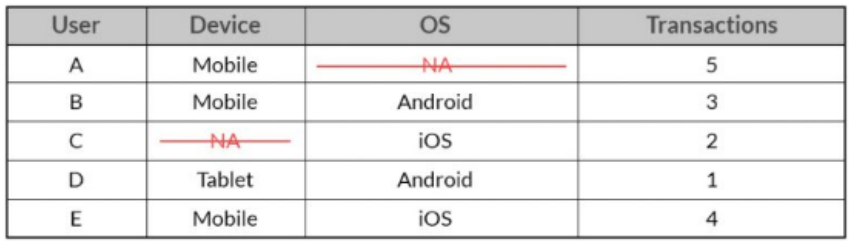
-
-
두번째 방법, 채우기
-
평균화 기법(Popular Averaging)
가장 널리 사용되는 기술로, 그룹의 평균값을 결측값에 채워준다.
결측치를 빠르게 채울 수 있는 장점이 있지만, 결측치들이 동일한 값도 가질 수 있기 때문에 데이터셋의 변동을 인위적으로 줄여줘야 한다.
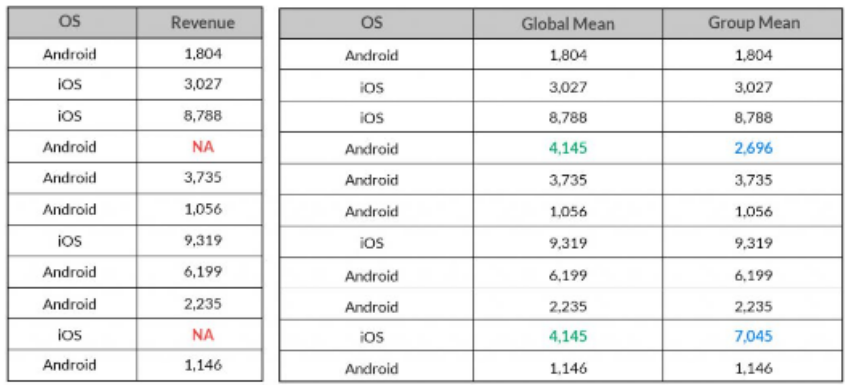
-
예측 기법(Predictive)
결측치들의 특성이 무작위로 완전히 관찰되지 않는다고 가정하고 예측모델을 사용하여 결측값을 대치할 예측값을 생성
회귀 분석 기술을 활용하거나 SVM과 같은 머신러닝 등의 데이터마이닝 방법을 사용
-
2. Feature별 상관관계, Heatmap 해석하기
Heatmap이란?
열을 의미하는 heat와 지도를 뜻하는 map을 합친 단어로 데이터들의 배열을 색상으로 표현
여러 카테고리 값에 대한 값 변화를 한눈에 알기 쉽다는 장점이 있다.
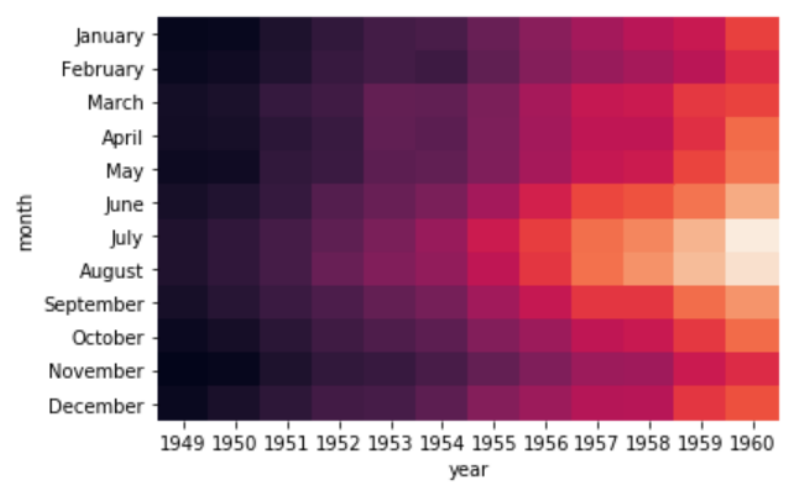
위의 데이터는 월별 비행기 이용 승객수이다. 빨간색이 짙을수록 승객수가 적음을 의미하고 빨간색이 얕아질수록 승객수가 높음을 의미한다.
데이터 형태가 테이블 형태일때보다 히트맵으로 나타내면 언제 승객이 많은지, 승객수 변화가 어떠한지 쉽게 알 수 있다.
3. Label Encoding VS One-Hot Encoding
머신러닝을 위한 대표적인 인코딩 방식으로 Label과 One-Hot이 존재한다.
-
레이블 인코딩은 간단하게 문자열 값을 숫자형 카테고리 값으로 변환한다.
그러나, 일괄적인 숫자값으로의 변환은 예측능력을 떨어트리는 원인이 될 수 있다.
숫자에 따라 각 카테고리들의 가중치 차이가 발생할 수 있기 때문으로 선형회귀와 같은
ML알고리즘에서는 맞지 않는다. -
원-핫 인코딩은 레이블 인코딩의 문제점을 해결하기 위한 인코딩 방식으로
feature값의 유형에 따라 새로운 feature를 추가하고 고유 값에 해당하는 칼럼에만 1을 표시하는 방식이다.
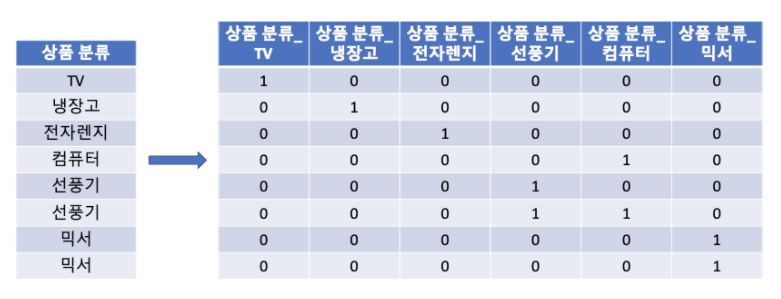
위의 사진은 가전제품 feature를 원-핫 인코딩을 걸친 것이다.
주의할 점이있다면 원-핫 인코딩하기 전에 모든 문자열 값이 숫자형 값으로 변환돼야 하며, 입력값으로 2차원 데이터가 필요하다는 것이다.